最近在研究gpu并行计算的问题,复习了下cuda的基本知识,可以和c混合编程,只不过里面有几个奇怪的函数,我们看如下的代码,文件名为cuda01.cu。
#include<cstdio>
#include<stdio.h>
__global__ void kernel()
{
printf("hello,world\n");
}
int main()
{
kernel<<<1,1>>>();
return 0;
}
接下来我们使用命令运行下
PS C:\Users\14499\Desktop\vsProjects\myCpp\cuda> nvcc .\cuda01.cu -o .\cuda01
cuda01.cu
正在创建库 .\cuda01.lib 和对象 .\cuda01.exp
PS C:\Users\14499\Desktop\vsProjects\myCpp\cuda> .\cuda01
hello,world
PS C:\Users\14499\Desktop\vsProjects\myCpp\cuda>
运行成功,这里__global__函数是核函数,在gpu上执行,从cpu上调用·,不能有返回值,从cpu端通过三重尖括号调用,除了__global__,还有__device__和__host__,如下代码
#include<cstdio>
#include <cstdlib>
#include<stdio.h>
__device__ __inline__ void say()
{
printf("say\n");
}
//定义核函数->在gpu上执行,可以有参数,不能有返回值,从cpu端通过三重尖括号调用
__global__ void kernel()
{
say();
printf("%d\n",threadIdx.x);
}
__host__ void speak()
{
printf("speak\n");
}
int main()
{
kernel<<<1,3>>>();
cudaDeviceSynchronize();//让cpu等待gpu完成所有的任务后再执行->从而在main函数退出前等待kernel在gpu上执行完
speak();
return 0;
}
__host__函数表示在cpu上运行的函数,可以不写,不写默认是__host__,__device__表示设备上的函数,在gpu上执行,从gpu上调用,不需要三重尖括号,和普通函数一样可以有返回值和参数,值得注意的是host可以调用global,global可以调用device,device可以调用device。运行结果如下所示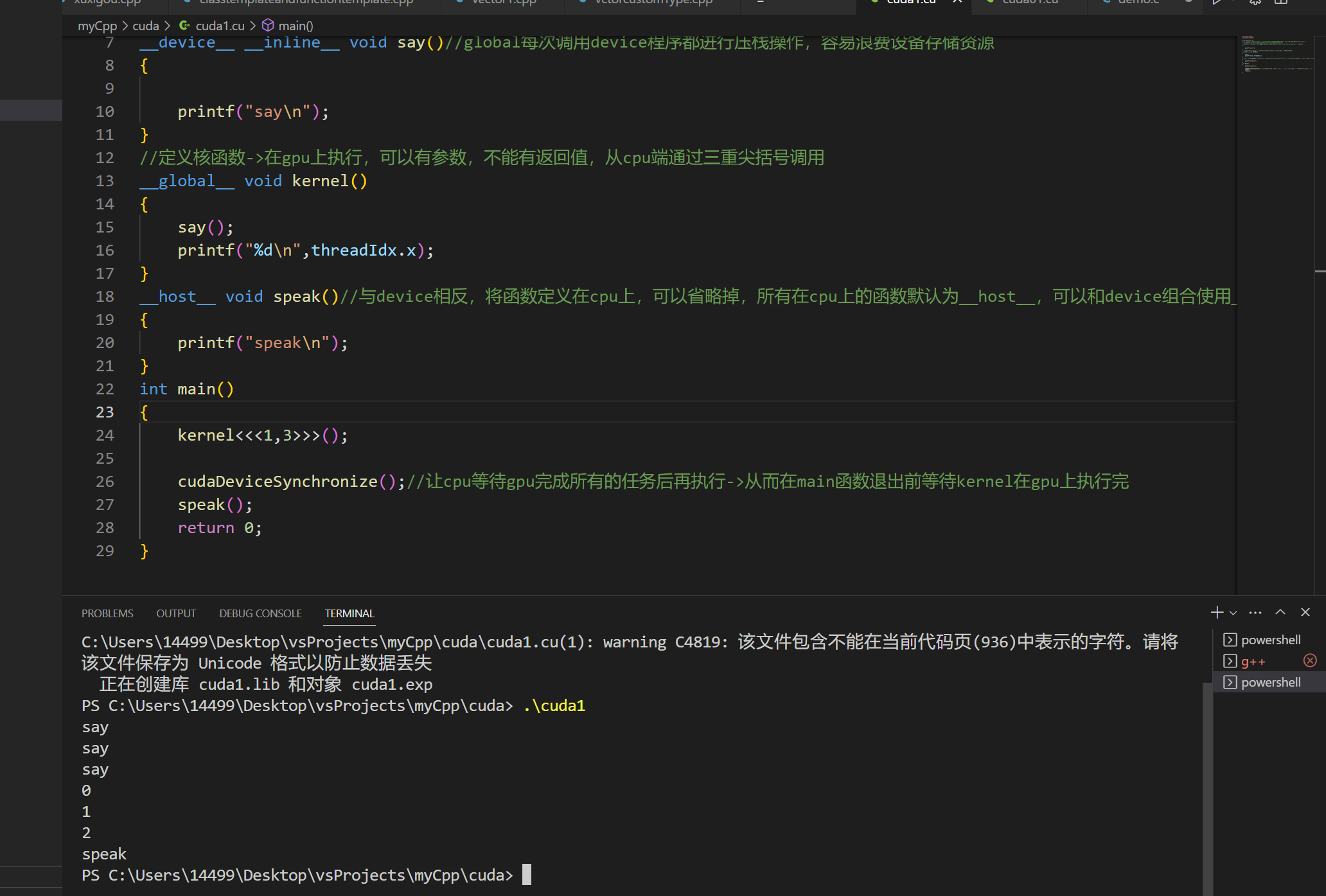 除此之外__host__和__device__可以结合使用,结合时表示既可以在cpu上执行又可以在gpu上执行,代码如下
除此之外__host__和__device__可以结合使用,结合时表示既可以在cpu上执行又可以在gpu上执行,代码如下
#include<cstdio>
#include<stdio.h>
__host__ __device__ void HD()
{
printf("host device\n");
}
__global__ void kernel()
{
printf("hello,world\n");
HD();
}
int main()
{
HD();
kernel<<<1,1>>>();
return 0;
}
结果如下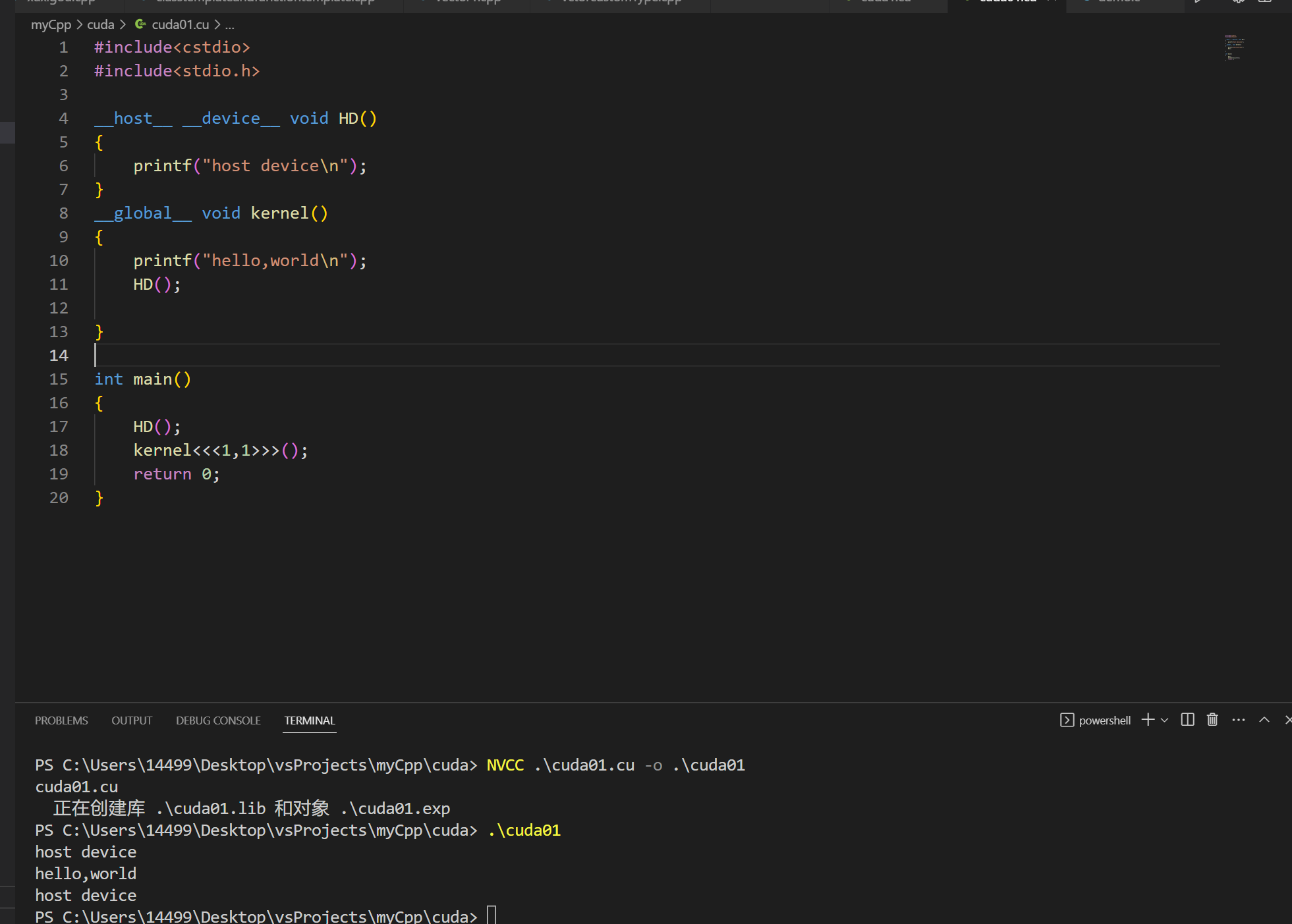 完美验证!
完美验证!
如果上述代码帮助您很多,可以打赏下以减少服务器的开支吗,万分感谢!



 赣公网安备 36092402000079号
赣公网安备 36092402000079号
点击此处登录后即可评论