最近没事想看下我们学校的微信公众号数据,对于我们搞代码的人来说直接干他,经过研究测试发现要想一次性全部搞下数据,得先注册下微信公众号号,在里面实现搜索翻页操作即可,话不多说,开干。登录微信公众号平台官网,注册了后点击草稿箱,然后点击图文模板,如图所示 点击新建图文模板,如图
点击新建图文模板,如图
点击超链接,如图所示 点击选择其他公众号,然后随便搜索一个公众号,这里我选择了我的学校公众号,如图所示
点击选择其他公众号,然后随便搜索一个公众号,这里我选择了我的学校公众号,如图所示 第一个公众号选择点击,可以看到页数,每页显示5条数据,如图所示
第一个公众号选择点击,可以看到页数,每页显示5条数据,如图所示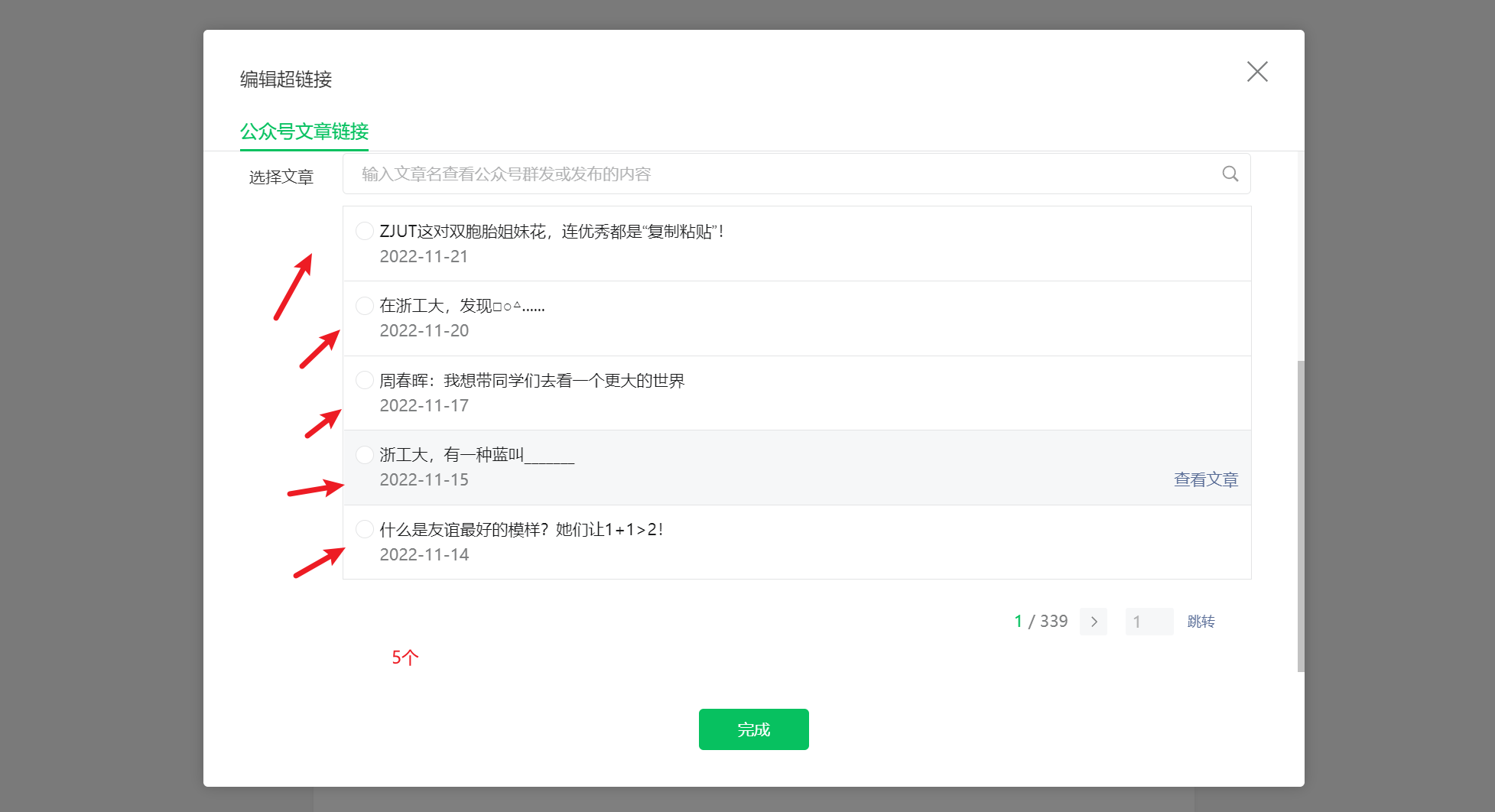 打开开发者工具,查看对应数据包,如图所示
打开开发者工具,查看对应数据包,如图所示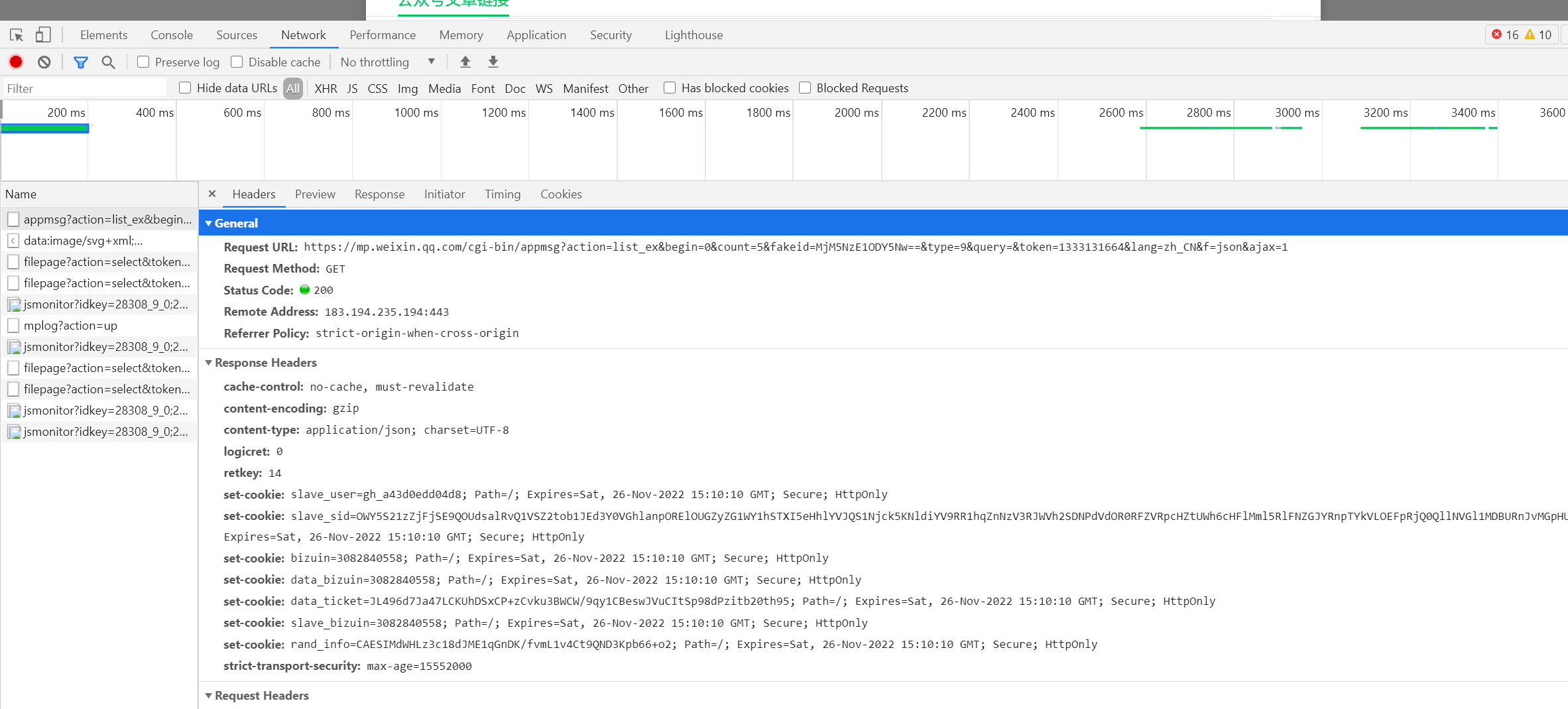
查看其参数,如图所示 接下来我们用代码模拟下,看下有没有数据包
接下来我们用代码模拟下,看下有没有数据包
import requests,os
import time,random
import pandas as pd
fakeid = 'MjM5NzE1ODY5Nw=='
headers = {
'cookie': 'appmsglist_action_3082840558=card; RK=X58tlA7FH3; ptcz=b2d24266d3479bef9c57ddd08f54442160dbfb6f88c2ee6a160fde97a91ae3a8; eas_sid=b1X6u6O8S8w497o4A5x3c2c1i8; pgv_pvid=9032741998; ua_id=s75eJXeRJxx1kvs8AAAAAOQIKmUqibpcFt7JJvUi8-U=; wxuin=69076741732777; rand_info=CAESIMdWHLz3c18dJME1qGnDK/fvmL1v4Ct9QND3Kpb66+o2; slave_bizuin=3082840558; data_bizuin=3082840558; bizuin=3082840558; data_ticket=JL496d7Ja47LCKUhDSxCP+zCvku3BWCW/9qy1CBeswJVuCItSp98dPzitb20th95; slave_sid=OWY5S21zZjFjSE9QOUdsalRvQ1VSZ2tob1JEd3Y0VGhlanpORElOUGZyZG1WY1hSTXI5eHhlYVJQS1Njck5KNldiYV9RR1hqZnNzV3RJWVh2SDNPdVdOR0RFZVRpcHZtUWh6cHFlMml5RlFNZGJYRnpTYkVLOEFpRjQ0QllNVGl1MDBURnJvMGpHUkw4eEJ2; slave_user=gh_a43d0edd04d8; xid=b45338820f535d59c7e66786c5ac70f1; mm_lang=zh_CN; _clck=3082840558|1|f6s|0; cert=StlHgRE5JoTrbW1I4Dv720nDXb7C4k_S',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.3',
}
def zh(time_sjc):
b = time.localtime(int(time_sjc))
c = time.strftime("%Y-%m-%d", b)
return c
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg'
for page in range(1,443):
params = {
'action': 'list_ex',
'begin': f'{(page-1)*5}',
'count': '5',
'fakeid': f'{fakeid}',
'type': '9',
'query': '',
'token': '1333131664',
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
}
r = requests.get(url,headers=headers,params=params,verify=False)
print('第{}页'.format(page))
print('*'*100)
print(r.json())
结果如下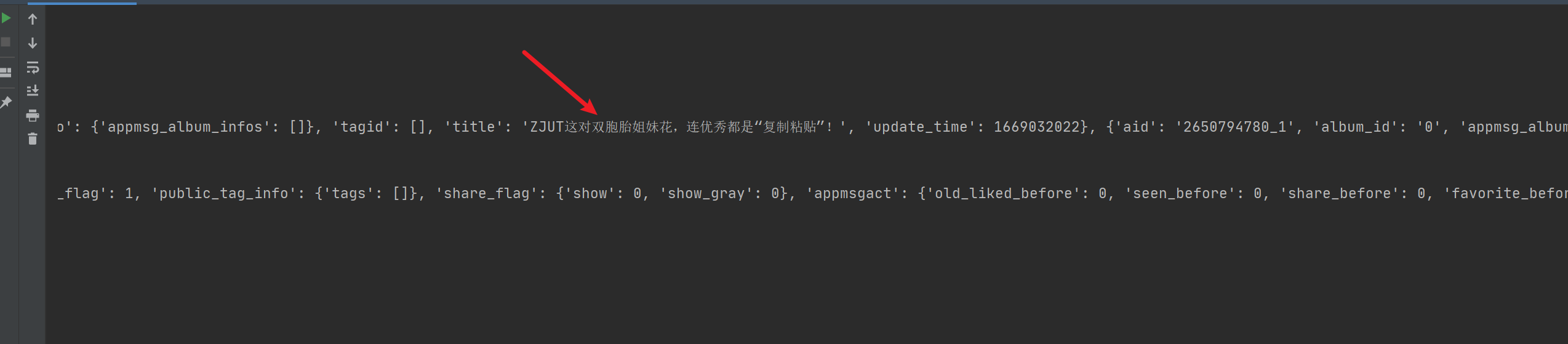
数据可以出来,现在要抓里面详情也的数据了,这里我用真机抓包下,打开微信公众号,点开上面箭头的第一条标题详情页,开始抓包,手机上第一条的数据如图所示
抓包的数据如图所示
查看url,发现是post请求,而且里面参数很多,为了不必要的参数我进行了测试,其中重要的参数是pass_ticket和appmsg_token,mid,sn,idx,__biz这几个,后面四个好办,直接在我们第一此代码请求结果中的link,如图所示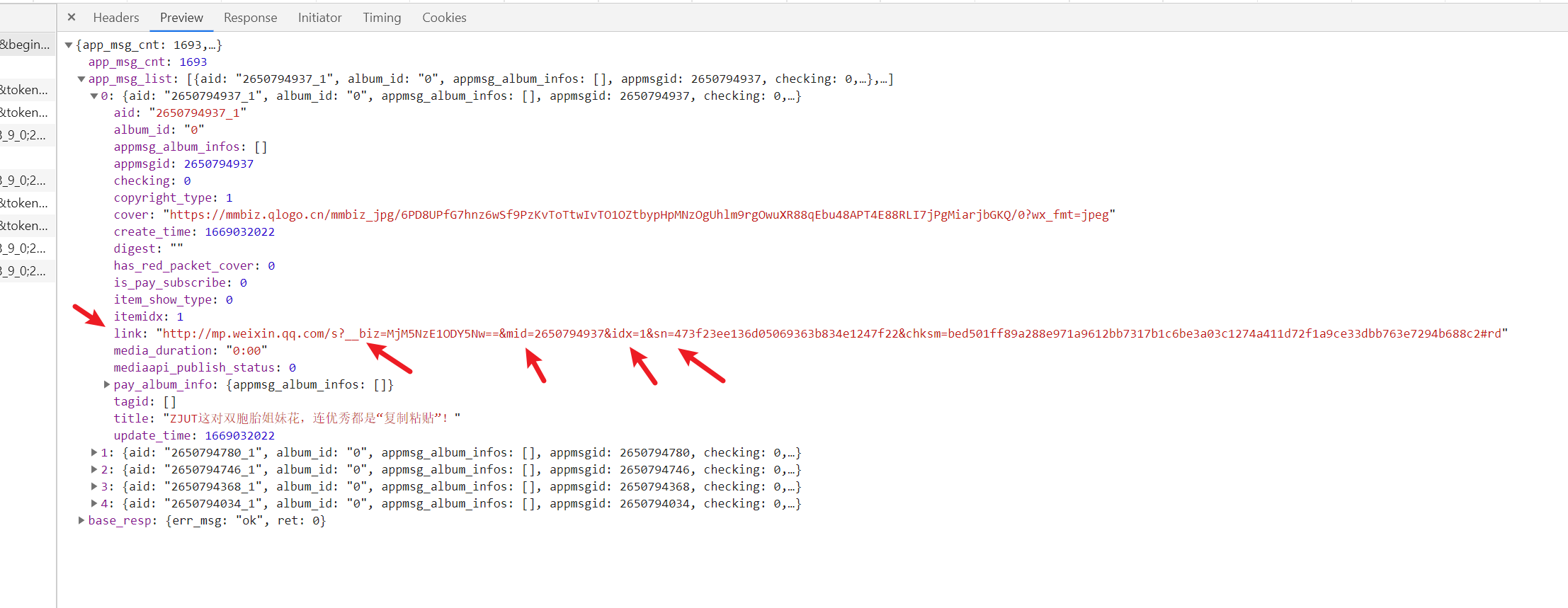 而前面2个参数就不知道咋搞了,经过测试发现不同公众号不一样,同一个公众号的都一样(无法实现批量公众号采集),好像过了一天后这2个就变了,针对我这个公众号这里姑且给他写死吧,link为详情页的数据,那么整体思路就很清晰了,先翻页请求数据,然后获取数据中的link详情链接,同时对链接进行分割获取__biz,mid,idx,sn。然后对link进行post请求,请求参数data为抓包里面的数据,里面包括pass_ticket和appmsg_token,很简单。思路有了,详细代码我就补贴了,直接看代码运行结果,如图所示
而前面2个参数就不知道咋搞了,经过测试发现不同公众号不一样,同一个公众号的都一样(无法实现批量公众号采集),好像过了一天后这2个就变了,针对我这个公众号这里姑且给他写死吧,link为详情页的数据,那么整体思路就很清晰了,先翻页请求数据,然后获取数据中的link详情链接,同时对链接进行分割获取__biz,mid,idx,sn。然后对link进行post请求,请求参数data为抓包里面的数据,里面包括pass_ticket和appmsg_token,很简单。思路有了,详细代码我就补贴了,直接看代码运行结果,如图所示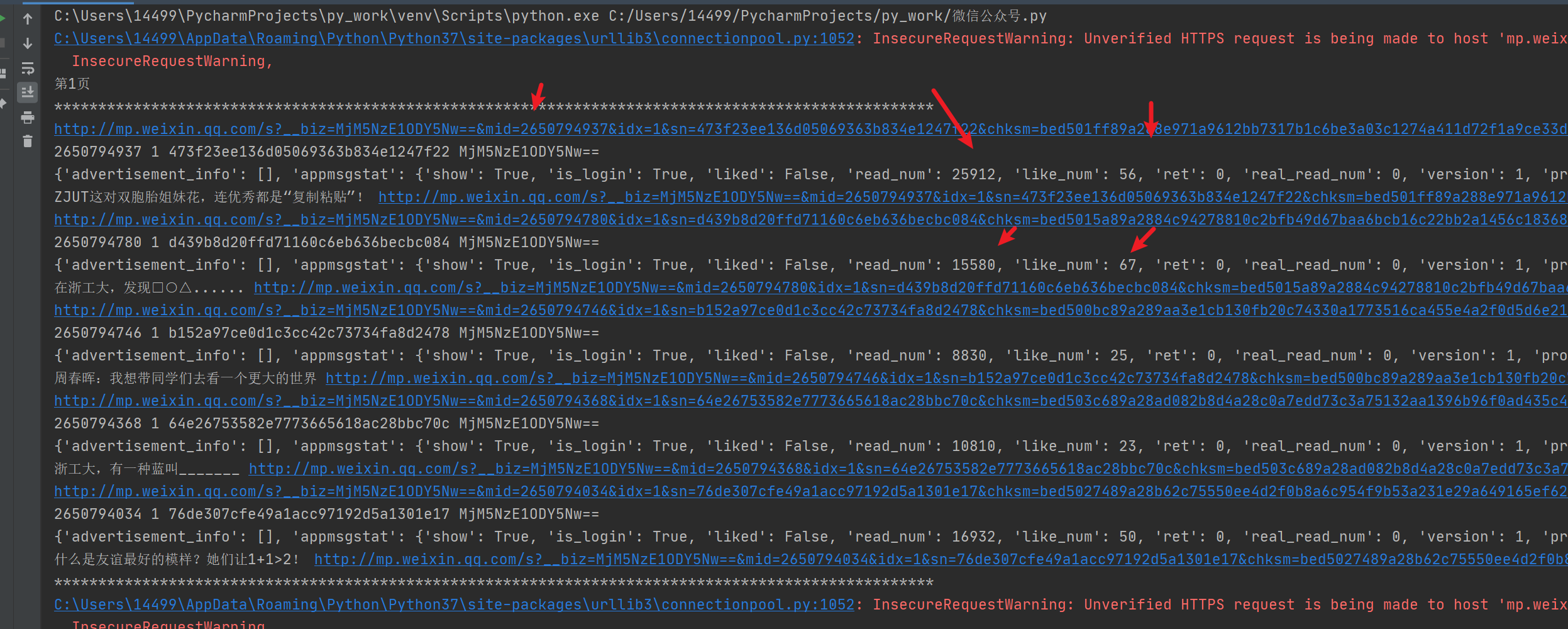 搞定!
搞定!
如果上述代码帮助您很多,可以打赏下以减少服务器的开支吗,万分感谢!



 赣公网安备 36092402000079号
赣公网安备 36092402000079号
点击此处登录后即可评论