之前接了一个单子,大概过了4个月了,原来的脚本没用了,客户要求维护,需求:输入用户主页链接,自动下载图片到本地,话不多说,开始撸代码,这个网站是国外的,vpn肯定得有,账号密码登录后,如图所示
以该例子为例,打开f12,不断下滑加载,查看xhr数据包状态,如图所示
查看该数据包的url参数,如图所示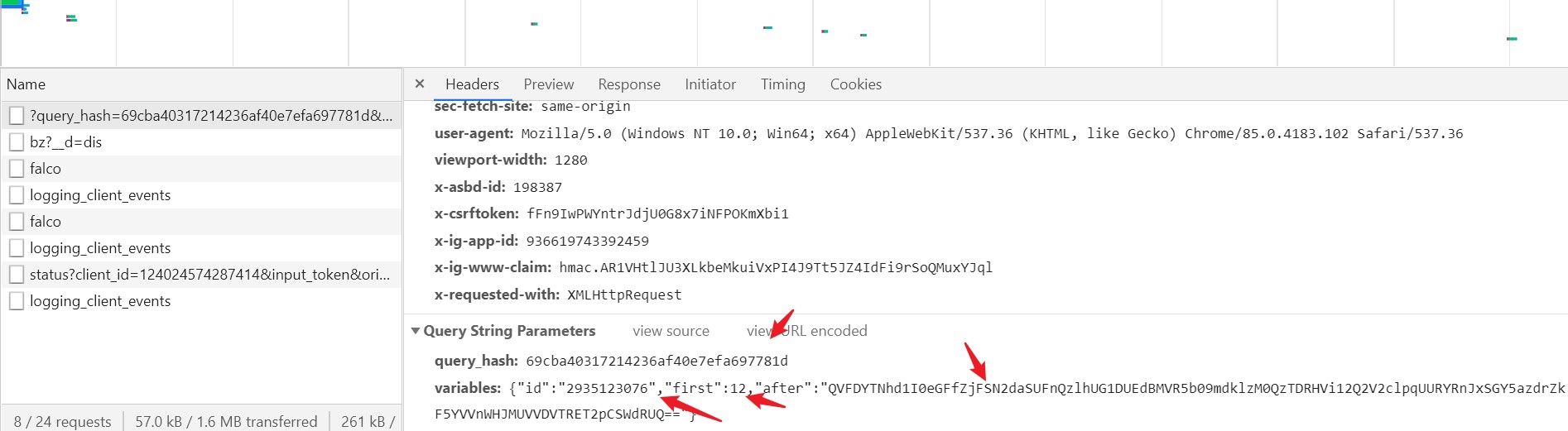
发现有2个参数,一个是query_hash,经过多次测试发现这个可以固定,还有一个是varibles,里面有个id,这个id是与用户名有关,全局查找,发现如图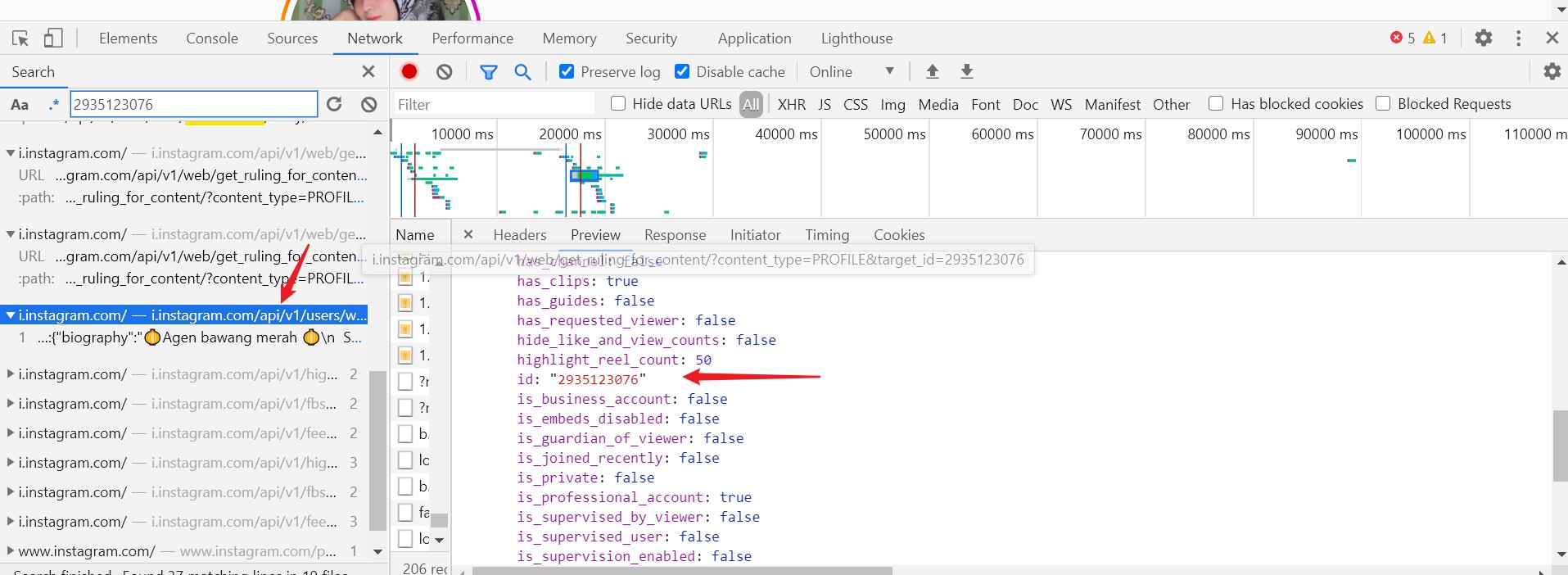
因此直接将该链接即可获取到id,现在还是first和after字段参数了,经过多次测试发现first是返回数据个数,固定返回12条数据,而after这个参数一般是和翻页有关的,即和page有关,发现返回的数据如图
一看就是end_cursor获得这个,那么翻页思路就明白了,那么第一页的end_cursor是怎么获取的呢,这个直接设置为空即可,测试后果真如此,注意的是全程都得带cookie,为了方便获取cookie,本次使用selenium自动化登录获取cookie,使用vpn代理下载图片到本地,直接上代码,如图
from selenium import webdriver
import time
import re,requests
import os
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
path = os.getcwd()
def f(url):
#配置项
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# prefs = {'profile.managed_default_content_settings.images': 2}
# chrome_options.add_experimental_option('prefs', prefs)
we_b = webdriver.Chrome(options=chrome_options)
#防止反爬
script = ''' Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) '''
we_b.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": script})
we_b.get(url)#浏览器打开
we_b.implicitly_wait(5)#隐式等待5秒
we_b.maximize_window()#最大化
return we_b
"""
https://scontent-sea1-1.cdninstagram.com/v/t51.2885-15/sh0.08/e35/c0.28.1440.1440a/s640x640/106485420_731083291026631_4819273436190898368
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
with open('password.txt','r',encoding='utf-8') as fi:
txt = fi.read()
print(txt)
zh ,mm = txt.split('-')
print(zh,mm)
link = input('输入要采集的链接:')
duankou = input('输入代理端口:(不输入默认10809)')
if not re.findall('\\d',duankou):
duankou = 10809
proxy = {
'https':'127.0.0.1:{}'.format(duankou),
'http':'127.0.0.1:{}'.format(duankou)
}
link1 = link+'channel/'
keyword = re.findall('https://www.instagram.com/(.*)/',link)[0]
if not os.path.exists(path+r'\{}'.format(keyword)):
os.mkdir(path+r'\{}'.format(keyword))
# if not os.path.exists(path+r'\{}'.format(keyword)+r'\视频'):
# os.mkdir(path+r'\{}'.format(keyword)+r'\视频')
if not os.path.exists(path+r'\{}'.format(keyword)+r'\照片'):
os.mkdir(path+r'\{}'.format(keyword)+r'\照片')
we_b = f('https://www.instagram.com/')
we_b.find_element_by_xpath('//input[@name="username"]').send_keys(zh)
time.sleep(1)
we_b.find_element_by_xpath('//input[@name="password"]').send_keys(mm)
time.sleep(1)
ActionChains(we_b).send_keys(Keys.ENTER).perform()
time.sleep(3)
cookies = {}
cookie = we_b.get_cookies()
for cc in cookie:
cookies[cc["name"]] = cc["value"]
print(cookies)
we_b.close()
print('扫描完成,开始采集')
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'x-ig-app-id': '936619743392459'
}
url_ = 'https://i.instagram.com/api/v1/users/web_profile_info/?username={}'.format(keyword)
r1 = requests.get(url_, headers=headers, proxies=proxy,cookies=cookies)
id = r1.json()['data']['user']['id']
print(id)
url = 'https://www.instagram.com/graphql/query/'
cursor = ""
num = 0
while True:
params = {
'query_hash': '69cba40317214236af40e7efa697781d',
'variables': '{"id":' + f"{str(id)}" + ',"first":12,"after":"{}"'.format(cursor) + """}""",
}
print(params)
r = requests.get(url, headers=headers, proxies=proxy, params=params,cookies=cookies)
print(r.url)
datas = r.json()['data']['user']['edge_owner_to_timeline_media']['edges']
has_next_pages = r.json()['data']['user']['edge_owner_to_timeline_media']['page_info']
has_next_page = has_next_pages['has_next_page']
print(has_next_page)
print(type(has_next_page))
for i in datas:
num += 1
print('正在采集第{}个'.format(num))
img_link = i['node']['display_url']
print(img_link)
rr = requests.get(img_link,headers=headers,proxies=proxy)
with open(path+r'\{}'.format(keyword)+r'\照片\{}.jpg'.format(num),'wb') as file:
file.write(rr.content)
if not has_next_page:
break
else:
cursor = has_next_pages['end_cursor']
time.sleep(0.5)
如果上述代码帮助您很多,可以打赏下以减少服务器的开支吗,万分感谢!



 赣公网安备 36092402000079号
赣公网安备 36092402000079号
点击此处登录后即可评论