先了解下机器学习吧,作为一种新的编程范式,机器学习系统是训练出来的,而不是明确地用程序编写出来的,对于经典的程序设计,一般是先编写对应规则的程序,然后输入数据,经过编写的程序规则经过计算即可得到想要的答案。而机器学习则是给出数据和对应的答案,经过训练得到答案和数据相对应的规则(一般称为假设函数),而绝大部分的数据和答案都可以通过这个规则(假设函数)进行映射。以下图很容易理解
机器学习里面种类很多,包括一些监督学习和无监督学习以及半监督学习,这个很容易区分,区分监督学习和无监督学习,直接看数据有无标签,无监督学习数据没有任何label(标签或标记)。什么叫label呢,比如说对房屋面积和价格进行预测,价格即为对应的数据标签,而房屋面积为特征。用通俗的话来说监督学习通过特征和标签对应的关系进行训练得到规则,而新的数据将新特征输入这个规则即可得到对应的新标签。而无监督学习数据则只有特征,没有标签,因此无法形成映射关系,也不知道结果是怎样,纯粹有计算机自行分析。对于监督学习一般分为2种,回归问题和分类问题,通常回归问题预测的是连续值,而分类问题预测的是离散值。比如预测房价,虽然是离散的,但对于实数可以认为是连续的因此归为回归问题,而对于预测肿瘤,根据之前的肿瘤大小和肿瘤结果数据,结果要么有要么没有,则归为分类问题。对于无监督学习,最基本的就是聚类了,只有特征数据,而没有结果数据,完全通过计算机算法将数据划分几个簇。无监督学习应用很多,像计算机集群,社交网络,谷歌新闻,天文数据分析,语音降噪等。在监督学习中,训练集包含3部分,训练样本数量m,输入特征变量x以及输入变量y,(x,y)表示一个训练样本,第i个训练样本则表示为(xi,yi)这里i为角标。监督学习算法工作流程如下所示
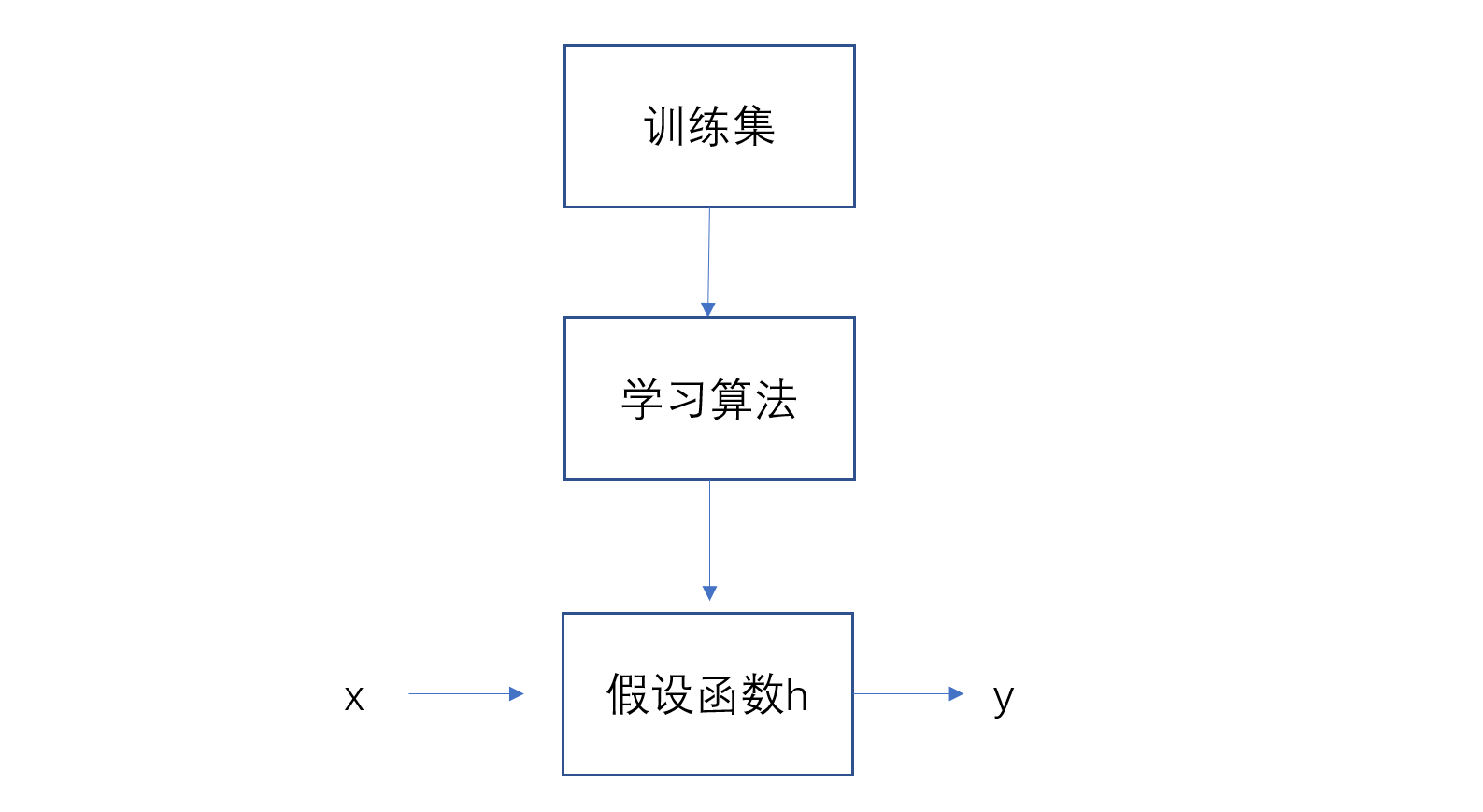
这里的假设函数h即为训练后得到的规则,这个规则来拟合初始的数据集。
如果上述代码帮助您很多,可以打赏下以减少服务器的开支吗,万分感谢!


 赣公网安备 36092402000079号
赣公网安备 36092402000079号
点击此处登录后即可评论