在机器学习中,梯度下降算法在监督学习扮演很重要的角色,先引例切入,现在有现成的房价数据集-波斯顿房价数据链接:https://pan.baidu.com/s/10y0k5q7PN-lK-YaP58fZfA 提取码:4izf ,里面有506个历史房屋样本,包含房间数和房价之间的关系,本次只讨论房间数对房价的影响,其他字段不用管,假如现在已知房间数,如何预测房价呢?为了直观认识房间数和房价的关系,运用python可视化散点图进行呈现,代码如下
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=[u'SimHei']
plt.rcParams['axes.unicode_minus']=False
data = pd.read_csv('C:/users/14499/desktop/housing.data')
def notEmpty(s):
return s!=''
#格式
df = np.empty((len(data), 14))
for i, d in enumerate(data.values):
m = map(float, filter(notEmpty, d[0].split(' ')))
df[i] = list(m)
print(df.shape)
names = ['CRIM','ZN', 'INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','MEDV']
df1 = pd.DataFrame(df,columns=names)
room_num = df1['RM']
price_num = df1['MEDV']
print(room_num)
print(price_num)
plt.scatter(room_num,price_num,s=100,c='green')
plt.title('房间数和房价关系')
plt.xlabel('房间数')
plt.ylabel('价格/(单位1000美元)')
plt.show()
结果如图所示
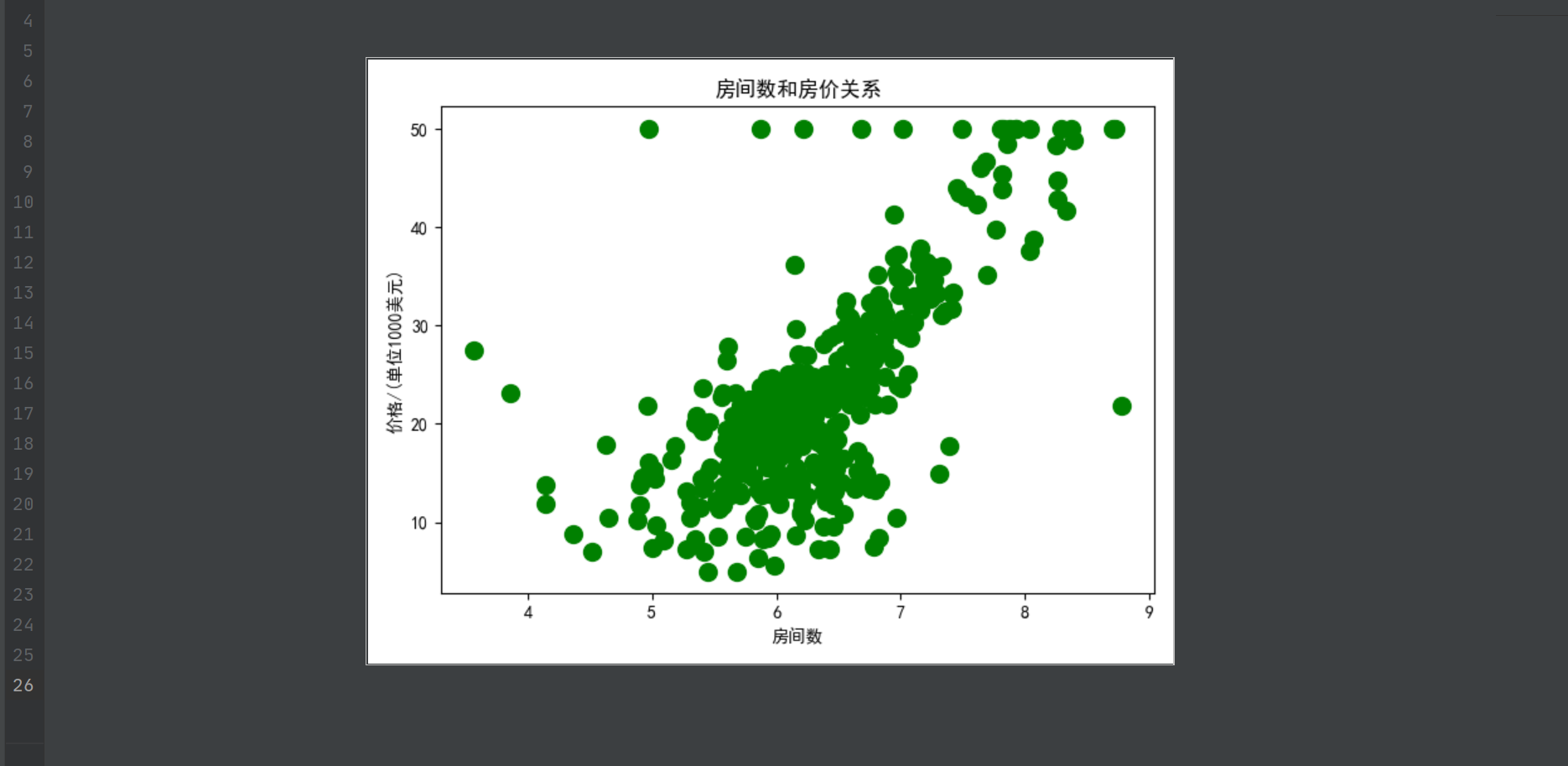
根据上述显示,可以用一个函数(规则)来拟合以上数据吗,当然可以,拟合方式有很多中,如下所示
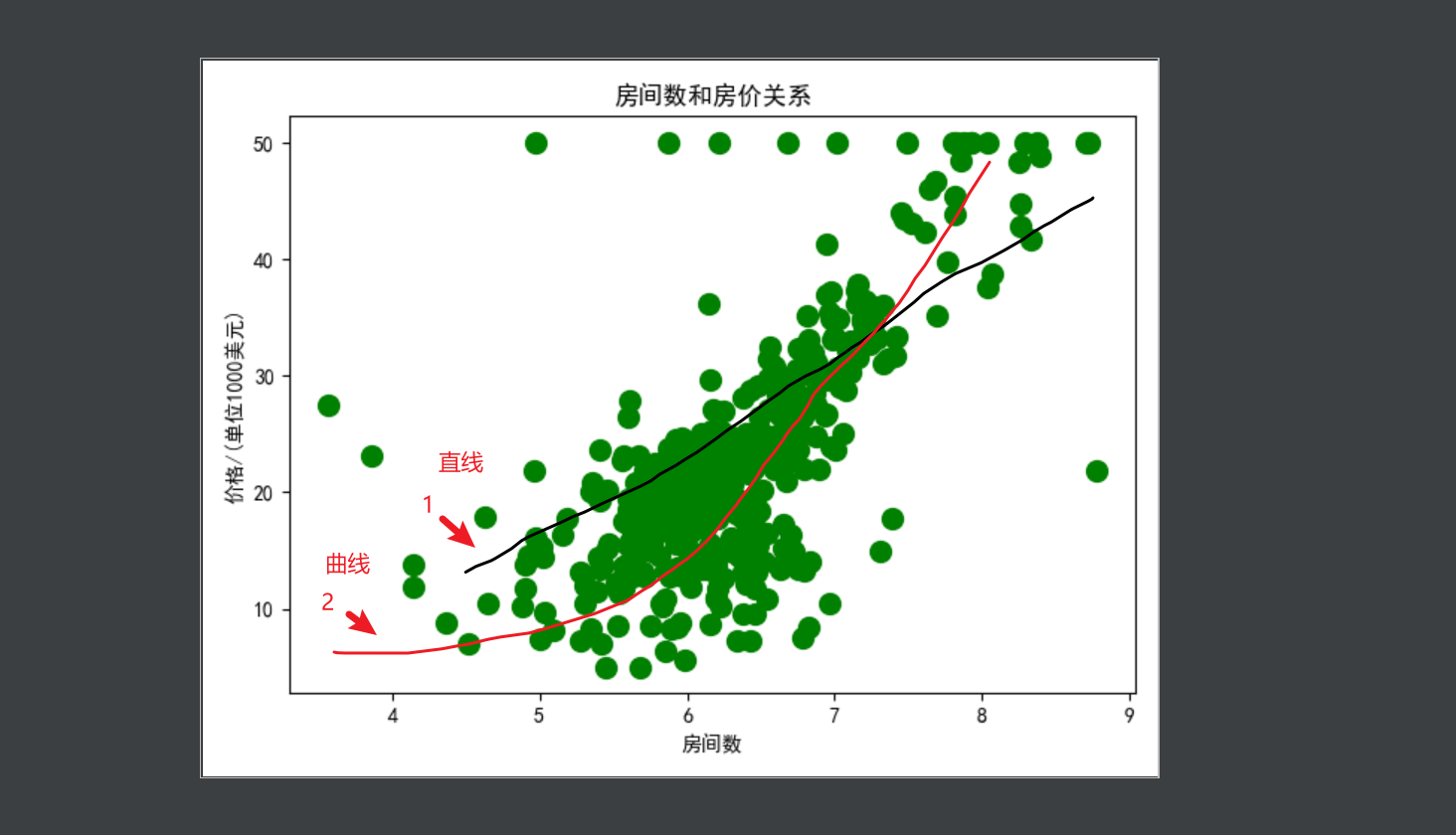
最简单的直接用直线来拟合,复杂点的用曲线来拟合都可以实现逼近原数据,最终的目的是是的拟合的函数和原来的数据相比误差最小,为了简单起见,本次使用直线来进行展示,很明显直线我们可以用一次函数进行表示h(x)=b0+b1*x,这里x为房间数,h(x)为价格,b0和b1为对应的截距和斜率,这里的h(x)函数一般称为假设函数(规则),要得到假设函数就要确定b0和b1的值,如何确定b0和b1来使得和原来的数据误差最小呢,因此我们引入误差函数(代价函数),为了更简洁,本次设置b0=0,即h(x)=b1*x,由于有的数据在直线上面,有的在下面,如果直接相减后再加和一正一负容易抵消,无法判断误差大小。因此使用平方来解决,误差公式:
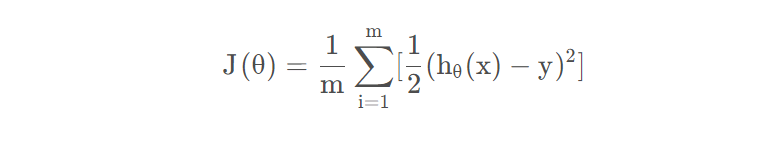
这里m为样本数,这里为什么是1/2m呢而不是1/m呢,这个无所谓,都行不影响最后参数结果,2只是为了后面求导抵消方便而已,不用纠结h(xi)为假设函数(规则)第i个样本的价格,y(i)为第i个样本的历史数据(训练集对应的数据),最后差的平方进行累加即可得到误差值。先看J这个函数,其变量是b1,因此可以称为J(b1)函数,我们可以将J(b1)与h(x)进行比较。为了简便起见,还是举例子吧,假设训练集数据集(1,1),(2,2),(3,3)这3个样本,假设b1=1即假设函数(规则)为h(x)=x,则可以计算误差J=0+0+0结果为0,再假设b=2,那么假设函数(规则)为h(x)=2*x,则J=(1+4+9)/6结果为2.3,以此类推,可以得到这2个函数的图像,如下所示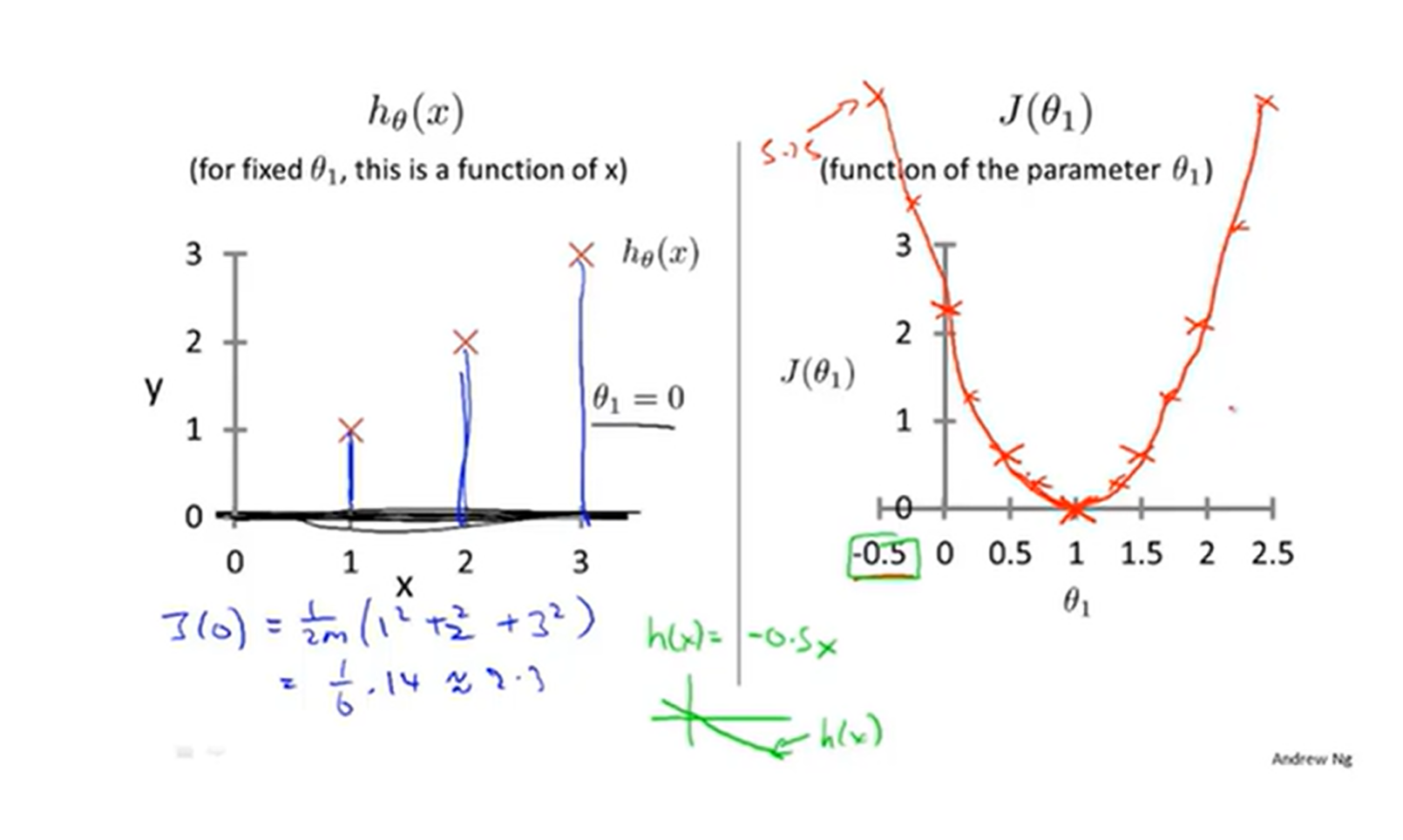
上面的变量不同不用管,可以随意设置的,可见J(b1)最小误差(代价函数)为b1=1时,即最拟合数据集的假设函数为h(x)=x,可以看见J函数为凸函数,有极值,这里b1=1为J的极小值也为最小值,但这是b0=0的结果,如果b0不等于0呢,J函数的图像是如何的,此时图像为3维了,如果你有想象空间应该不难看出类似一个碗底的形状,如下所示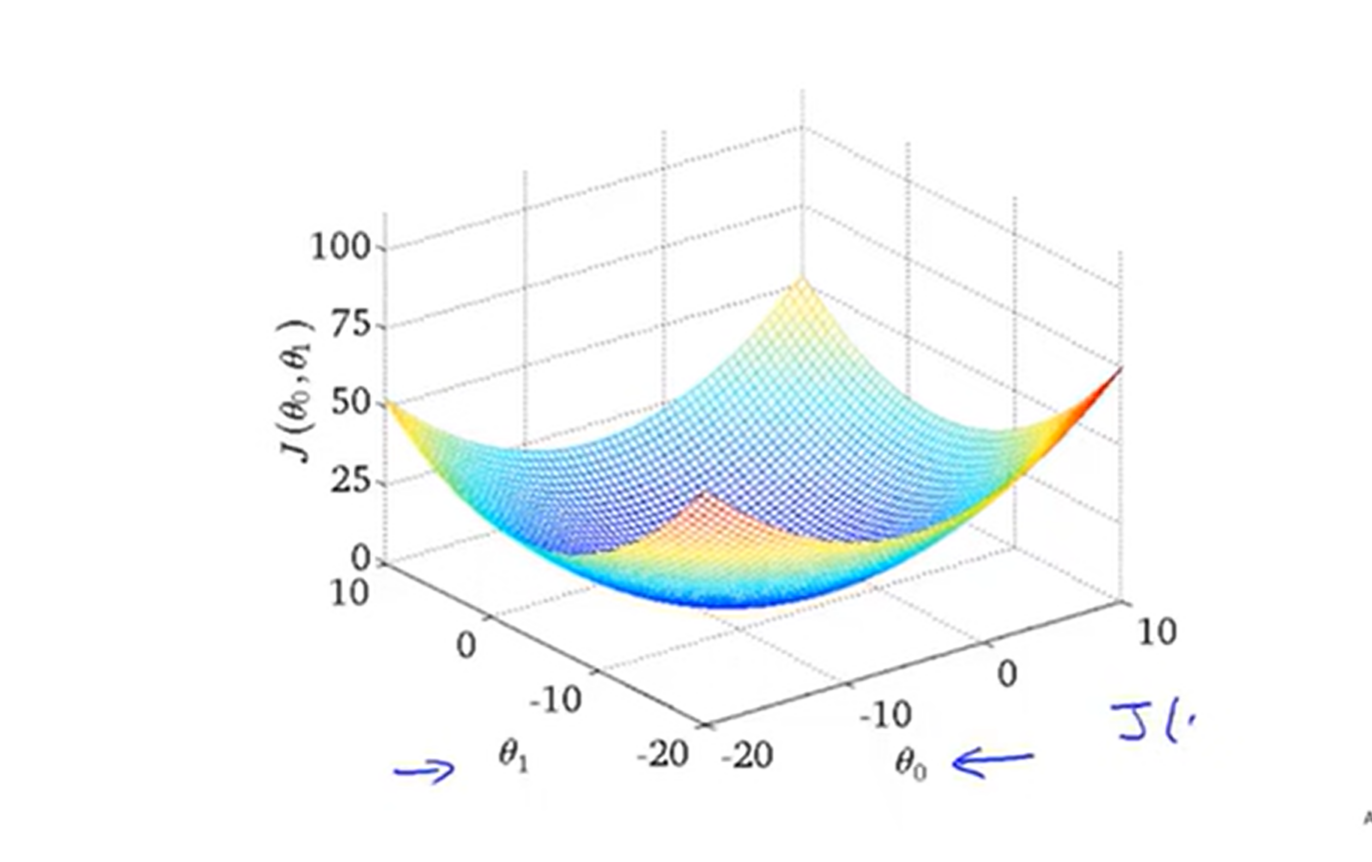
,对于这样的3维图如何求J的极小值呢,这就得引入梯度的概念了,对于二维的函数,取极值直接进行求导即可(函数可导),现在3维,可以分别对b0和b1方向分别求偏导,求得的偏导再矢量相加即为梯度,在数学意义上称为变化最快的方向了,那就很好理解了。梯度下降可以理解为每次往最快的方向移动,直到移动到最低点为止。对于代码我们可以分为2步,1给定初始值b0和b1,2不断同步更新b0和b1知道不变为止。
如上所示,这里的字符改成所对应的b0和b1即可。分别对b0和b1求偏导,这里的alpha为学习率,自己设定即可,这里的同步更新b0和b1可能有点不理解,可以大致画下J(b0,b1)的图像,可以固定b0,二维显示凸函数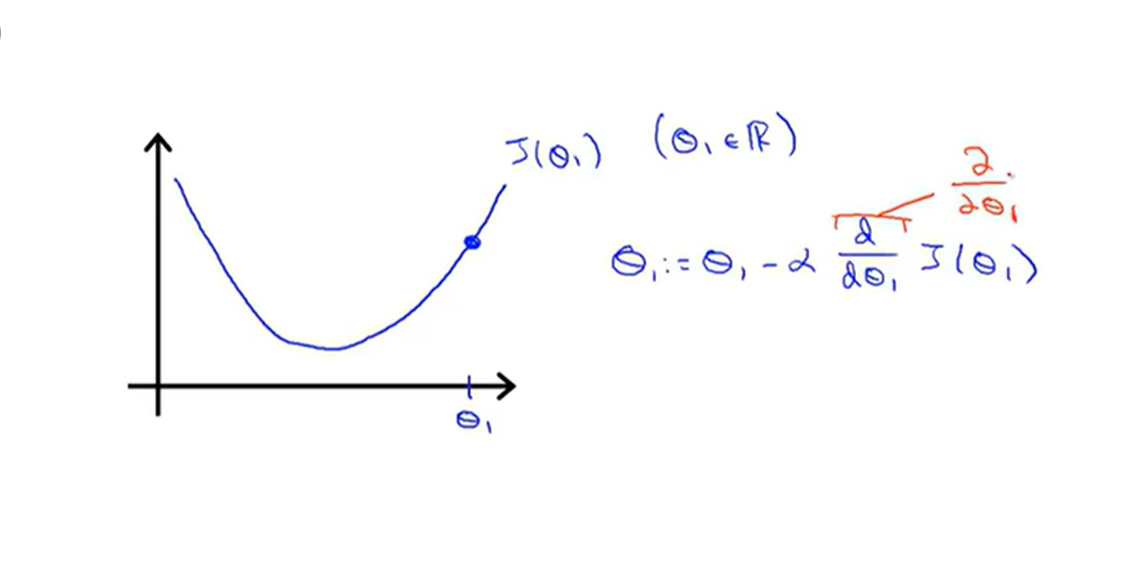
比如在这个点,对b1的偏导大于0,而一般学习率为正数,根据更新公式b1=b1-alpha*J对b1的偏导可见b1往左移动,同理,直到偏导为0时b1即不再更新,即为局部最优点,为什么说是局部最优点呢,如果3维图像如下所示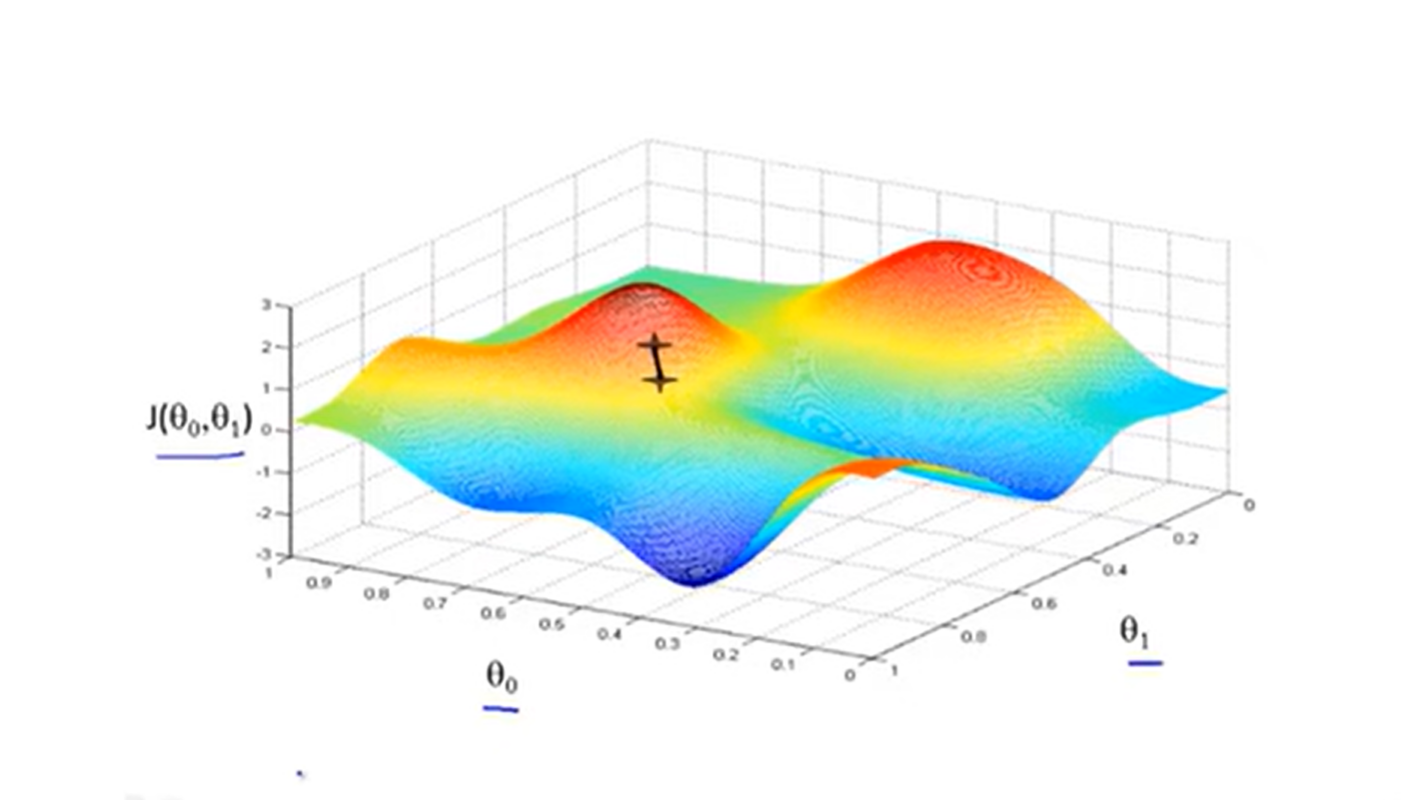
像这样可能有个平坦处,即有多个局部最优解,那哪个是最小值点呢,这是梯度下降算法的一个难解决的问题,除此之外通过公式可以看到学习率的选择也容易影响迭代次数,尽管如此,梯度下降算法仍对于大数据量预测来说一个很好的解决方法,再用通俗的话来理解下梯度:想象一下漆黑的夜里,你在一座高山上面,你只有一直手电筒,只能照亮你脚下的路,那么你应该怎么样才能下到山底去?肯定是只要眼前是下坡,就往下走,一直走下去就可以到山底。
如果上述代码帮助您很多,可以打赏下以减少服务器的开支吗,万分感谢!


 赣公网安备 36092402000079号
赣公网安备 36092402000079号
点击此处登录后即可评论