之前客户有个需求,想要批量导出他的王者荣耀战绩,试想应该不难就接了,开始想直接抓王者荣耀游戏的包,发现上面的历史战绩只保存1周的,后面想到王者营地,开始尝试,发现只有3个月的历史战绩,经过仔细调查才发现,王者后台历史战绩只会保留3个月的数据,想来也正常,这么多用户,数据存这么多岂不是要好多数据库,这样一来直接省钱多了,永远保留最新的3个月的历史战绩,话不多说,开始撸代码,下载好王者营地app,可到官网直接下载,这里我用模拟器上操作,连接fiddler,点击个人主页,战绩显示,如图所示

那就好办,点开该数据包,查看其参数,发现参数很多,不慌,直接copy下来,经过多次测试发现,翻页变动的参数就是lasttime这个了,而第一个的lasttime为0,而其对应的响应包含下一页的lasttime,这样翻页思路就有了,对于响应字段,里面包含heroId,这个对应某个英雄,如图所示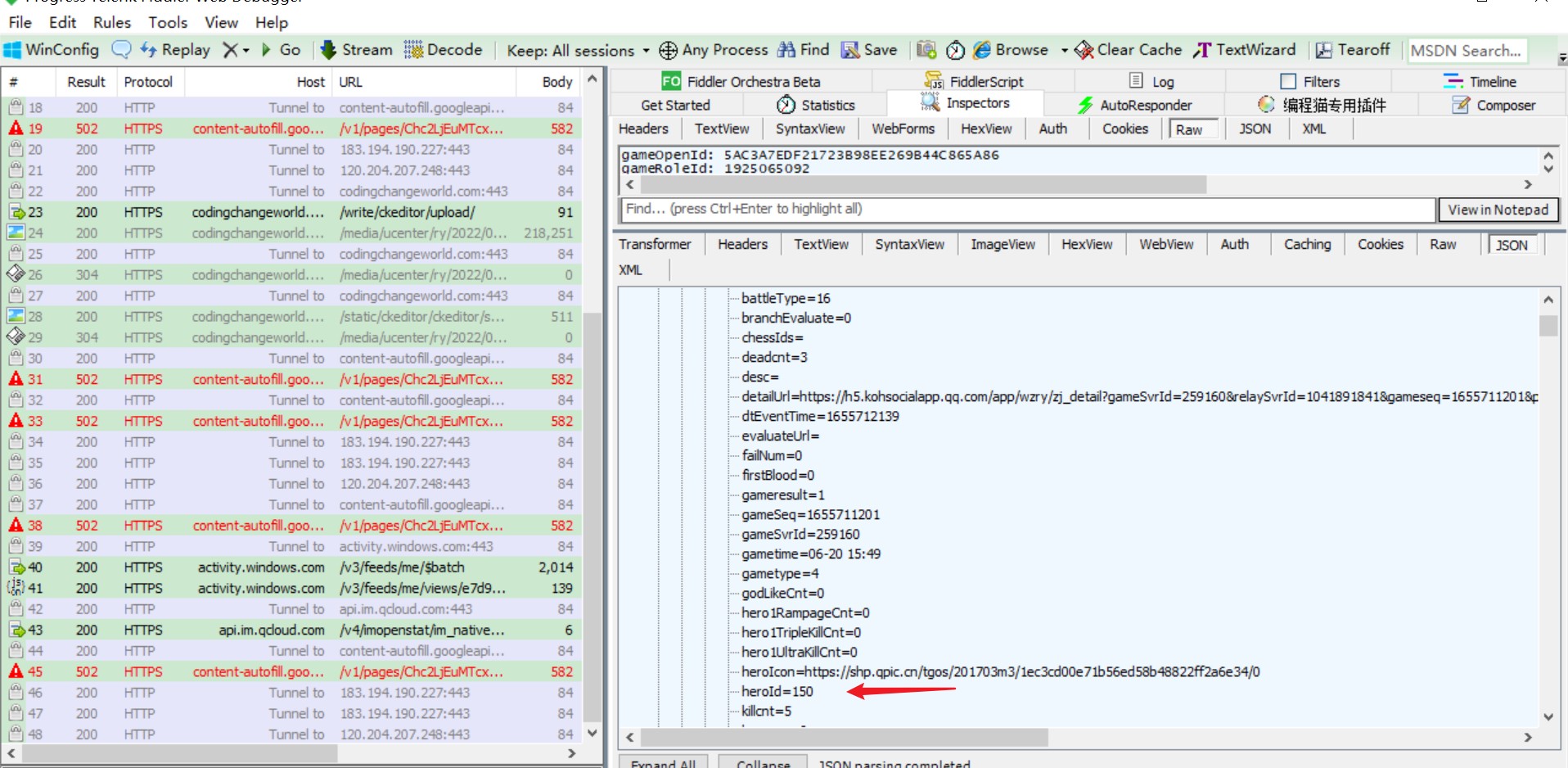
经过多次研究发现网页端有id和英雄建立的映射,那么就好办了,先查看网页获取字典映射,如图
查看数据包,如图所示
字典映射代码如图所示
index_url = 'https://pvp.qq.com/web201605/js/herolist.json'
headers_2 = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
r2 = requests.get(index_url,headers=headers_2)
r2.encoding = r2.apparent_encoding
msgs = r2.json()
zd_1 = {}
for jk in msgs:
zd_1[jk['ename']] = jk['cname']
接下来就获取对应的字段了,一个一个取值,没啥看头。注意的是,如何判断翻页结束呢,可以根据haseMore字段来,如果为False,则break,否则一直采集,代码如下
import requests
from lxml import etree
import re
import time
headers = {
'cChannelId': '10002483',
'cCurrentGameId': '20001',
'cGameId': '20001',
'gameAreaId': '1',
'gameId': '20001',
'gameOpenId': '5AC3A7EDF21723B98EE269B44C865A86',
'gameRoleId': '1925065092',
'gameServerId': '1283',
'gameUserSex': '1',
'openId': '376C7053A0271477DF39C3CAC9798C59',
'tinkerId': '2022673205_64_0',
'token': '自己的登录验证',
'userId': '499569202',
'User-Agent': 'okhttp/4.9.1'
}
#主页
data_1 = {
'friendUserId':'499569202',
'noMatch':'0',
'roleId':'1925065092',
'rsVersion':'3',
'cChannelId':'10002483',
'cClientVersionCode':'2022673205',
'cClientVersionName':'6.73.205',
'cCurrentGameId':'20001',
'cGameId':'20001',
'cGzip':'1',
'cRand':'1655644619115',
'gameAreaId':'1',
'gameId':'20001',
'gameOpenId':'5AC3A7EDF21723B98EE269B44C865A86',
'gameRoleId':'1925065092',
'gameServerId':'1283',
'gameUserSex':'1',
'openId':'376C7053A0271477DF39C3CAC9798C59',
'tinkerId':'2022673205_64_0',
'token':'自己的登录验证',
'userId':'499569202'
}
#
index_url = 'https://pvp.qq.com/web201605/js/herolist.json'
headers_2 = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
r2 = requests.get(index_url,headers=headers_2)
r2.encoding = r2.apparent_encoding
msgs = r2.json()
zd_1 = {}
for jk in msgs:
zd_1[jk['ename']] = jk['cname']
nums = 0
time_id = 0
while True:
data = {"lastTime":f"{time_id}","apiVersion":4,"option":0,"friendUserId":"填自己的","friendRoleId":"填自己的"}
url = 'https://kohcamp.qq.com/game/morebattlelist'
r = requests.post(url,headers=headers,json=data)
print(r.json())
datas = r.json()['data']
time_id = datas['lastTime']
pd = datas['hasMore']
result = datas['list']
for i in result:
nums += 1
kill_num = i['killcnt']
die_num = i['deadcnt']
help_num = i['assistcnt']
desc = i['desc']
if not desc:
desc = '无'
heroId = int(i['heroId'])
hero = zd_1[heroId]
gameresult = i['gameresult']
if int(gameresult) == 2:
gameresult = '输'
else:
gameresult = '赢'
heroIcon = i['heroIcon']
mapName = i['mapName']
dw = i['roleJobName']+'{}星'.format(i['stars'])
print('第{}次采集'.format(nums))
print('当前段位:{},比赛类型:{},使用英雄:{},击杀人数:{},死亡数:{},助攻数:{},对战结果:{},英雄id:{},描述:{},英雄图片:{}'.format(dw,mapName,hero,kill_num,die_num,help_num,gameresult,heroId,desc,heroIcon))
time.sleep(1)
if not pd:
break
注意下token为自己的登录验证,frienduserid和friendroleid是用户的id,如果你想采集别人的数据换成他们对应的就可以了,为了安全,我就不贴出自己的来了,最后运行结果显示如图
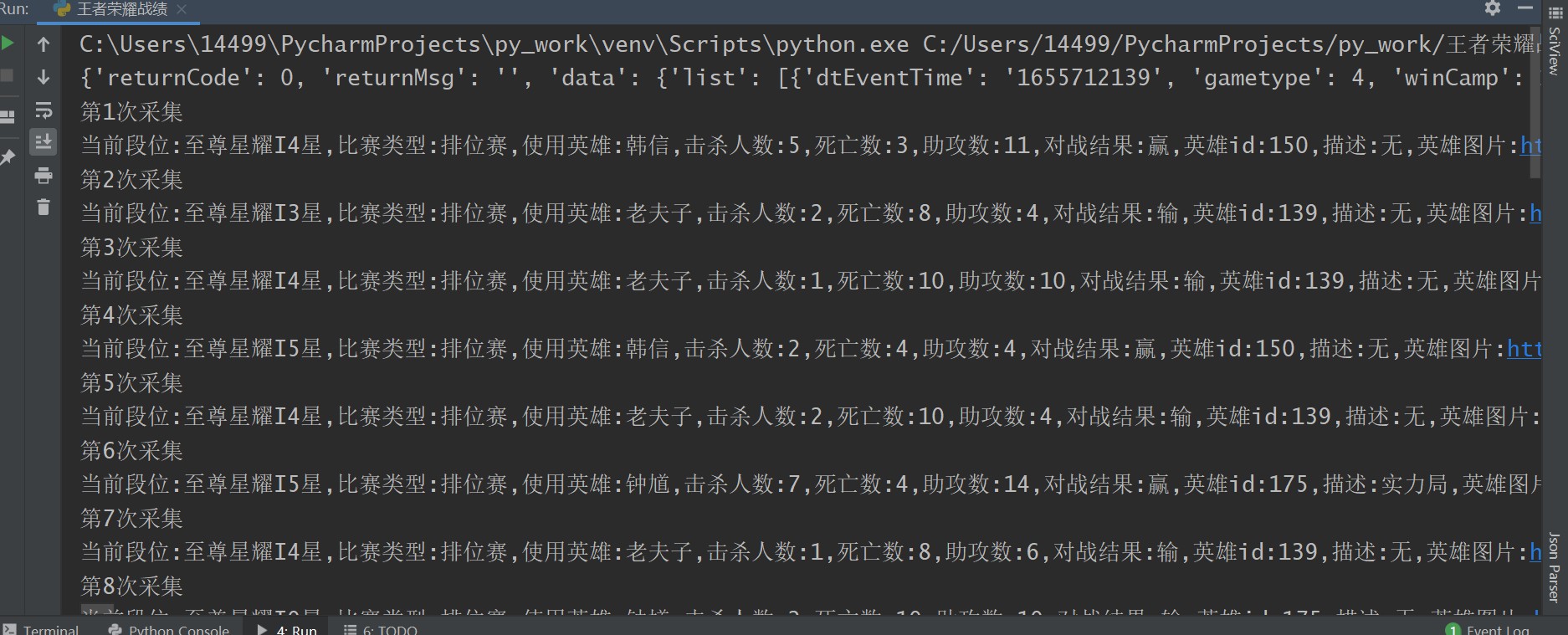
说明下,这个是采集qq区的。这个采集的针对玩家未隐藏战绩的,如果玩家隐藏战绩,则无法实现采集,想采集玩家隐藏战绩的就不用看我的了,去联系王者荣耀的内部人员吧,可能他们有对应接口
如果上述代码帮助您很多,可以打赏下以减少服务器的开支吗,万分感谢!



 赣公网安备 36092402000079号
赣公网安备 36092402000079号
点击此处登录后即可评论